Have you ever thought about setting up a repository of specific info, and then using a language model to query that info to give you dependent answers? For example, if you had the full text of a book, or many books and wanted to find that exact section that has information on your specific topic, you could retrieve it via a retrieval system and language model. Or if you had a list of all of the difficult scenarios you encountered in your job, with solutions to each, you could retrieve them too – this process is part of an AI framework called RAG or Retrieval-Augmented Generation. Such a processes uses embeddings which are divided into manageable chunks and then a query process retrieves them. Such data can be stored in PDFs/TXTs (text) or a vector database. One process to find out which chunks or embeddings are best for retrieval is called cosign similarity which is a mathematical computation that determines the distance between two vectors and hence validates the similarity between each text grouping and retrieves the most relevant information.
Below we have broken this process down into its simplest parts and attempted some explanations as well as borrowed a few DLLs which will be loaded into PowerShell via reflection: AllMiniLmL6V2Sharp.dll & Microsoft.ML.OnnxRuntime.dll. These can be retrieved in Visual Studio Code via NuGet, via dotnet add package or downloaded via the links above and are used for Tokenizing and Embedding and are compatible with Dotnet 2 Standard.
Note: To run dotnet add package, you will need an actual Visual Studio Project File (CSPROJ), from VSCode choose: Terminal > New Terminal:
winget install Microsoft.DotNet.SDK.6
dotnet nuget add source https://api.nuget.org/v3/index.json -n nuget.org
dotnet new classlib -f netstandard2.0 -o MyProject
CD MyConsoleApp
dotnet add package AllMiniLmL6V2Sharp --version 0.0.3
dotnet add package Microsoft.ML.OnnxRuntimeFor the sake of this exercise, all required files are in C:\Users\ADMIN\vector_content\ – make sure to copy AllMiniLmL6V2Sharp.dll & Microsoft.ML.OnnxRuntime.dll to that location. You’ll also need model.onnx and vocab.txt in the same location, so be sure to download those and move them over now. You can find them after successful installation under: ~\.nuget\packages\allminilml6v2sharp\0.0.3\lib\netstandard2.1\AllMiniLmL6V2Sharp.dll & ~\.nuget\packages\microsoft.ml.onnxruntime\1.22.0\runtimes\win-x64\native\onnxruntime.dll
In addition you’ll need ollama server, this will be your local language model that will interpret your results – this is installed quite easily via PowerShell as well:
winget install ollama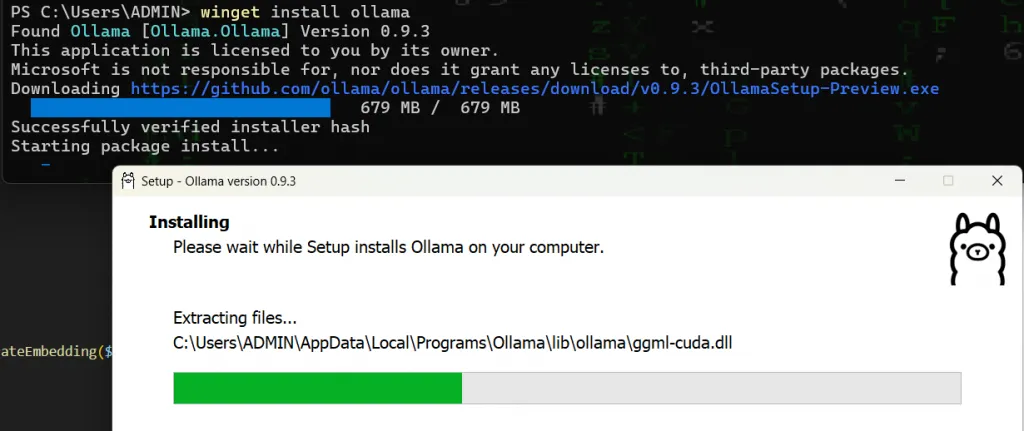
After installing ollama, you may want to set a PATH variable for the location – eg: C:\Users\ADMIN\AppData\Local\Programs\Ollama – you can do this in Windows under: Advanced system settings > Environment Variables – Modify the “Path” variable via [Edit] > [New]. Remember you’ll need to reload PowerShell to reflect the new PATH variable.
To automatically download and run the llama3.2 model, type:
ollama run llama3.2
After initially loading the model, you can test it out. You should be surprised at how much information the small 2GB model has packed into it. After verifying the model is working – close it with the command /bye and ollama stop llama3.2. Now run the model again in server mode with the command:
/bye
ollama stop llama3.2
ollama serveNote, you may also need to close ollama from the icon next to your clock before you can run it again in server mode:
Once Ollama is running in server mode, you’ll notice diagnostic outputs in your PowerShell window, be sure to open a new PowerShell window to proceed with the next steps

You should now be able to query Ollama via the addresses mentioned here. If you want Ollama server to listen on all interfaces, instead of just your loopback (127.0.0.1) be sure to add the environment variable: OLLAMA_HOST=0.0.0.0. Note that a standard curl works here and Ollama server runs on port 11434 by default. We can do a simple test, however we do just need to provide some json in the form of a post body – for example:
$body = @{
model = "llama3.2"
prompt = "what's crackalackin?"
stream = $false
} | ConvertTo-Json -Depth 10
$request = Invoke-RestMethod -Uri "http://127.0.0.1:11434/api/generate" -Method Post -Body $body -ContentType 'application/json'
$request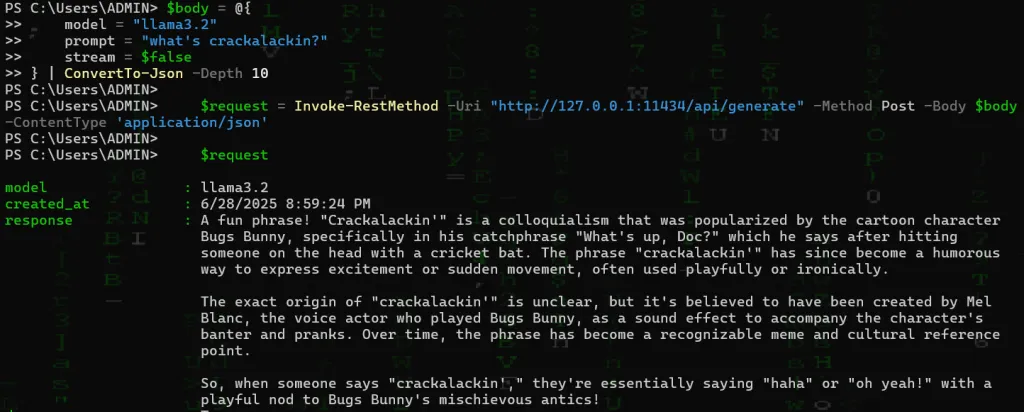
In the above example, we’ve asked our language model “what’s crackalackin?” and received a response. From here we can ask whatever we like and provide context and ask the model to answer questions based on that context. For example, based on the following context, which types of cars are faster?
$body = @{
model = "llama3.2"
prompt = "based on the following context only, which types of cars are faster? Context: Red cars are the fastest, following by black cars and then white cars are the slowest"
stream = $false
} | ConvertTo-Json -Depth 10
$request = Invoke-RestMethod -Uri "http://127.0.0.1:11434/api/generate" -Method Post -Body $body -ContentType 'application/json'
$request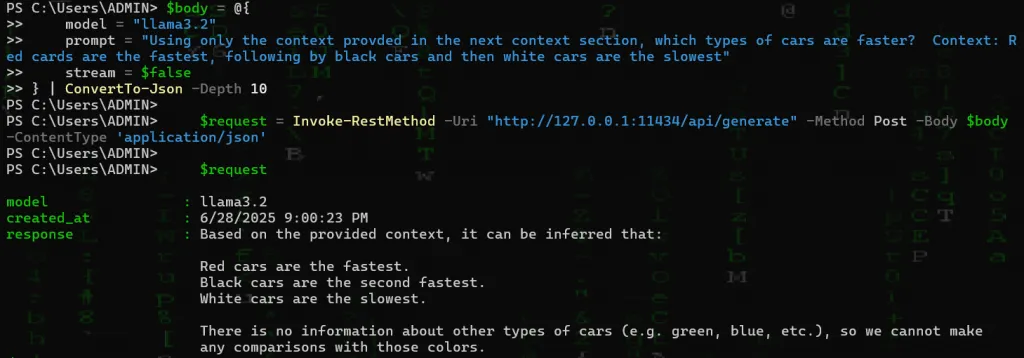
Note, we see HTTP response 200 from our server window where we ran ollama serve:

The above example may seem silly, but it brings up exactly what we will be doing moving forward which is proposing a question and then providing the exact context required with which to answer that question. In the example, the prompt was to utilize only the context provided which indicated that red cars were faster than black and white cars. Moving forward, we’ll be running cosign similarity to locate the exact context or embeddings to provide and then the action will be the same as to where the model will answer our question based on that context.
Here is the full PowerShell script:
## Required to run ollama in Windows via ##
## winget install ollama
## Set Path C:\Users\ADMIN\AppData\Local\Programs\Ollama\
## Set var OLLAMA_GPU_LAYER=cuda (requires winget install nvidia.cuda - check via nvidia-smi)
## ollama run llama3.2
## or ollama serve if you set variables like:
## OLLAMA_HOST 0.0.0.0
## Spefic to PS7 due to dotNET2 core
## Vector Context ##
## https://aka.ms/dotnet/download
## dotnet add package AllMiniLmL6V2Sharp --version 0.0.3
## dotnet add package Microsoft.ML.OnnxRuntime
# Load the AllMiniLML6v2Sharp assembly & MS ONNX
[System.Reflection.Assembly]::LoadFrom("C:\Users\ADMIN\vector_content\AllMiniLmL6V2Sharp.dll")
[System.Reflection.Assembly]::LoadFrom("C:\Users\ADMIN\vector_content\Microsoft.ML.OnnxRuntime.dll")
# Set model and vocab paths
$modelPath = "C:\Users\ADMIN\vector_content\model\model.onnx"
$vocabPath = "C:\Users\ADMIN\vector_content\model\vocab.txt"
# Create the tokenizer (with vocab)
$tokenizer = [AllMiniLML6V2Sharp.Tokenizer.BertTokenizer]::new($vocabPath)
# Create the embedder (with model and tokenizer)
$embedder = [AllMiniLML6V2Sharp.AllMiniLmL6V2Embedder]::new($modelPath, $tokenizer, $false)
# Load and chunk your context
$content = Get-Content "C:\Users\ADMIN\vector_content\content.txt" -Raw
$maxWords = 256
$words = $content -split '\s+'
$chunks = @()
for ($i = 0; $i -lt $words.Length; $i += $maxWords) {
$chunk = $words[$i..([Math]::Min($i + $maxWords - 1, $words.Length - 1))] -join ' '
$chunks += $chunk
}
# Generate embeddings for each chunk
$contextEmbeddings = @()
foreach ($chunk in $chunks) {
try {
$contextEmbeddings += [PSCustomObject]@{ Text = $chunk; Embedding = $embedder.GenerateEmbedding($chunk) }
} catch { }
}
while ($true) {
$ask = Read-Host "`nlla(^_^)aBot"
# Generate embedding for the user's question
$questionEmbedding = $embedder.GenerateEmbedding($ask)
# Find the most similar context chunk (cosine similarity)
function CosineSimilarity($a, $b) {
$dot = 0; $normA = 0; $normB = 0
for ($i = 0; $i -lt $a.Count; $i++) {
$dot += $a[$i] * $b[$i]
$normA += [Math]::Pow($a[$i], 2)
$normB += [Math]::Pow($b[$i], 2)
}
if ($normA -eq 0 -or $normB -eq 0) { return 0 }
return $dot / ([Math]::Sqrt($normA) * [Math]::Sqrt($normB))
}
$bestScore = -1
$bestChunk = ""
foreach ($item in $contextEmbeddings) {
$score = CosineSimilarity $questionEmbedding $item.Embedding
if ($score -gt $bestScore) {
$bestScore = $score
$bestChunk = $item.Text
}
}
# Output the selected context chunk
Write-Host "`nSelected Context Chunk`n======================`n$bestChunk`n"
# Compose prompt with strict instructions
$prompt = @"
As a helpful technician answer the following question based on the information provided in the Context section below.
The context is provided from scenearios I have participated in the past and each scenario is formatted listing the issue, the cause and the resolution
If the answer is not in the context, reply "I don't see a previous scenario for this."
Be sure to bulletize relevant links at the end of your answer and the scenario ID to cite relative context.
Context:
$bestChunk
Question:
$ask
"@
$body = @{
model = "llama3.2"
prompt = $prompt
stream = $false
} | ConvertTo-Json -Depth 10
$request = Invoke-RestMethod -Uri "http://127.0.0.1:11434/api/generate" -Method Post -Body $body -ContentType 'application/json'
$content = $request.response
$content, "`n"
}We can see that:
- Our DLLs are loaded via Reflection or [System.Reflection.Assembly]::LoadFrom(…
- The model and vocabulary paths that were downloaded from Huggingface were set via $modelPath & $vocabPath
- We created a Tokenizer with AllMiniLML6V2Sharp via the $tokenizer object
- Our content should be created & located in …\vector_content\content.txt and then is split into $chunks
- Embeddings are created from each chunk via PSCustomObject $embedder
- And finally the $bestChunk is found via function CosineSimilarity and provided in our prompt later on in our curl/Invoke-RestRequest to Ollama server to interpret our results
Let’s ask ChatGPT to explain what Cosign Similarity is to us, from our previous post:
Query ChatGPT 4o Search Preview from PowerShell for free like a boss!
ask “explain cosign similarity and how it’s used in RAG LLM like I am 12”
Imagine you have two arrows pointing in different directions. The angle between these arrows tells you how similar their directions are. If the arrows point in the same direction, the angle is small, and if they point in opposite directions, the angle is large. Cosine similarity is a way to measure this angle between two arrows, or in math terms, between two vectors. It helps us understand how similar two things are based on their direction, regardless of their length.
In the world of computers and language, we often turn words or sentences into numbers called vectors. These vectors capture the meaning of the words. When we want to find out how similar two pieces of text are, we can compare their vectors using cosine similarity. A higher cosine similarity means the texts are more alike.
Now, let’s talk about Retrieval-Augmented Generation (RAG). This is a fancy way of saying that when a computer tries to answer a question, it first looks up relevant information before generating a response. Here’s how cosine similarity fits into this process:
- Turning Text into Vectors: Both the question you ask and the documents the computer has are converted into vectors.
- Comparing Vectors: The computer uses cosine similarity to compare your question’s vector with the vectors of the documents. This helps the computer find which documents are most related to your question.
- Finding the Best Match: The documents with vectors that have the highest cosine similarity to your question’s vector are considered the best matches.
- Generating an Answer: The computer uses the information from these top-matching documents to craft a well-informed answer to your question.
By using cosine similarity, the computer can effectively find and use the most relevant information, making its answers more accurate and helpful.
For this test I will use the following context.txt where I’ve defined some answers to some very specific technical scenarios, but you should fill context.txt with anything you want, for example your favorite novel could be a great test.
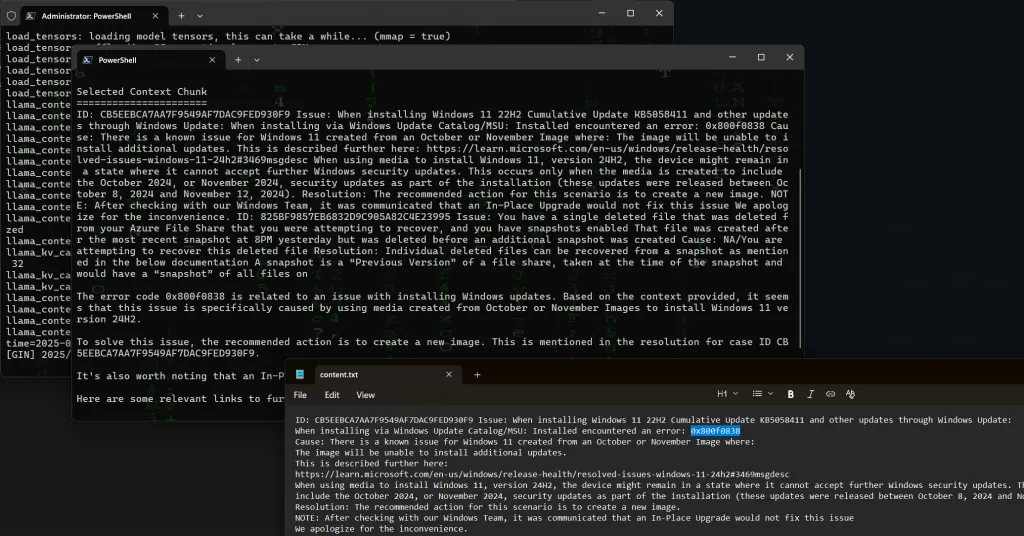
Here I have asked:
lla(^_^)aBot: how do i solve windows update error 0x800f0838?
Let’s try a readily available book The Catcher And The Rye and copy and paste its contents into your content.txt – we’ll also need to change up our prompt a bit:
## Required to run ollama in Windows via ##
## winget install ollama
## Set Path C:\Users\ADMIN\AppData\Local\Programs\Ollama\
## Set var OLLAMA_GPU_LAYER=cuda (requires winget install nvidia.cuda - check via nvidia-smi)
## ollama run llama3.2
## or ollama serve if you set variables like:
## OLLAMA_HOST 0.0.0.0
## Spefic to PS7 due to dotNET2 core
## Vector Context ##
## https://aka.ms/dotnet/download
## dotnet add package AllMiniLmL6V2Sharp --version 0.0.3
## dotnet add package Microsoft.ML.OnnxRuntime
# Load the AllMiniLML6v2Sharp assembly & MS ONNX
[System.Reflection.Assembly]::LoadFrom("C:\Users\ADMIN\vector_content\AllMiniLmL6V2Sharp.dll")
[System.Reflection.Assembly]::LoadFrom("C:\Users\ADMIN\vector_content\Microsoft.ML.OnnxRuntime.dll")
# Set model and vocab paths
$modelPath = "C:\Users\ADMIN\vector_content\model\model.onnx"
$vocabPath = "C:\Users\ADMIN\vector_content\model\vocab.txt"
# Create the tokenizer (with vocab)
$tokenizer = [AllMiniLML6V2Sharp.Tokenizer.BertTokenizer]::new($vocabPath)
# Create the embedder (with model and tokenizer)
$embedder = [AllMiniLML6V2Sharp.AllMiniLmL6V2Embedder]::new($modelPath, $tokenizer, $false)
# Load and chunk your context
$content = Get-Content "C:\Users\ADMIN\vector_content\content.txt" -Raw
$maxWords = 256
$words = $content -split '\s+'
$chunks = @()
for ($i = 0; $i -lt $words.Length; $i += $maxWords) {
$chunk = $words[$i..([Math]::Min($i + $maxWords - 1, $words.Length - 1))] -join ' '
$chunks += $chunk
}
# Generate embeddings for each chunk
$contextEmbeddings = @()
foreach ($chunk in $chunks) {
try {
$contextEmbeddings += [PSCustomObject]@{ Text = $chunk; Embedding = $embedder.GenerateEmbedding($chunk) }
} catch { }
}
while ($true) {
$ask = Read-Host "`nlla(^_^)aBot"
# Generate embedding for the user's question
$questionEmbedding = $embedder.GenerateEmbedding($ask)
# Find the most similar context chunk (cosine similarity)
function CosineSimilarity($a, $b) {
$dot = 0; $normA = 0; $normB = 0
for ($i = 0; $i -lt $a.Count; $i++) {
$dot += $a[$i] * $b[$i]
$normA += [Math]::Pow($a[$i], 2)
$normB += [Math]::Pow($b[$i], 2)
}
if ($normA -eq 0 -or $normB -eq 0) { return 0 }
return $dot / ([Math]::Sqrt($normA) * [Math]::Sqrt($normB))
}
$bestScore = -1
$bestChunk = ""
foreach ($item in $contextEmbeddings) {
$score = CosineSimilarity $questionEmbedding $item.Embedding
if ($score -gt $bestScore) {
$bestScore = $score
$bestChunk = $item.Text
}
}
# Output the selected context chunk
Write-Host "`nSelected Context Chunk`n======================`n$bestChunk`n"
# Compose prompt with strict instructions
$prompt = @"
As a helpful reader answer the following question in the question section based on the information provided in the Context which is a book excerpt.
If the answer is not in the context, reply "I don't context for this.
Context:
$bestChunk
Question:
$ask
"@
$body = @{
model = "llama3.2"
prompt = $prompt
stream = $false
} | ConvertTo-Json -Depth 10
$request = Invoke-RestMethod -Uri "http://127.0.0.1:11434/api/generate" -Method Post -Body $body -ContentType 'application/json'
$content = $request.response
$content, "`n"
}Notice we removed the parts about scenario IDs and to bulletize links and changed our prompt to be much more aligned with excerpts from a book:
What’s an embedding anyway?
We can actually see this visually if we continue to source our code via . .\scriptname.ps1 as all variables remain in memory after ending our script, just like bash. As we understand all variables default to standard out, the output for $questionEmbedding is as follows:
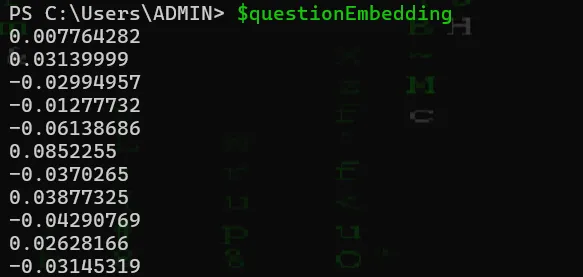
Hence, we see that our embedding here to our language model are just math and an arrangement of numbers. In fact, an embedding is a numerical representation of a piece of text, such as a word, sentence, or document with high-dimensional vectors that capture the semantic meaning of that text. These vectors are what allow the comparison of language via our cosign similarity mathematical comparison.
Note of course, you can comment out or remove the section which displays the selected context chunk (# Write-Host “`nSelected Context Chunk`n======================`n$bestChunk`n” on line 77) in addition to rewording your context to thinks like: answer the following question in the question section based only on the information provided in the Context …
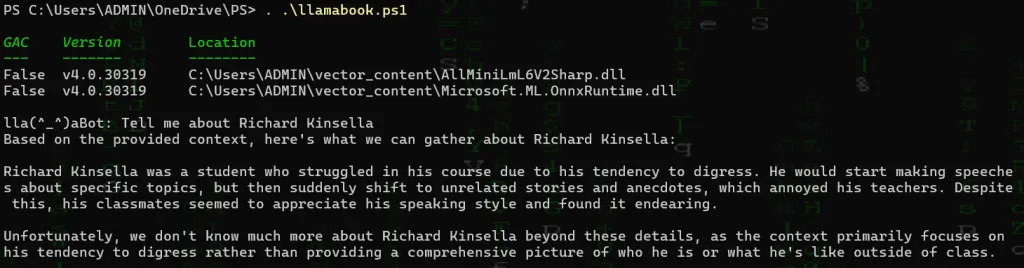
Notice the limited information for such a popular topic if we change our code and mention to only take our context into consideration -eg:
$prompt = @"
As a helpful reader answer the following question in the question section based only on the information provided in the Context which is a book excerpt.
If the answer is not in the context, reply: I don't have context for this.
Context:
$bestChunk
Question:
$ask
"@We hope you enjoyed this basic tutorial of creating a RAG. Note that it is intentionally simplistic. In larger applications, you may look at retrieving data through a vector database such as Chroma DB.